- PDFのみの提供です
- 紙書籍も必要な場合は、こちらからお得なセットをお求めください
- 紙書籍のみを差額等でお求め頂くことはできません
そのプログラム、CPUの性能を引き出せますか?
ソフトウェアの価値は、ハードウェアで実行されることにより、現実のものになります。そのために不可欠なのがCPUです。したがってソフトウェアの価値は、CPUの性能、すなわち「できるだけ高速にソフトウェアを実行すること」にかかっているとも言えるでしょう。
現代のCPUの性能は、「メモリとやり取りしながら命令を実行していく」というCPUの原理的な仕組みを知るだけでは説明できません。ソフトウェアを高速に実行するためにCPUシステムが備えているパイプライン化やスーパースカラ化の挙動をはじめ、アウトオブオーダー実行、分岐予測、キャッシュ、TLBといった高速化のためのハードウェア機構、さらにはI/Oやシステムコールなどの例外・割り込み系がCPUの動作に及ぼす影響について、幅広く知る必要があります。
さらに、現在では広く利用されているマルチプロセッサのCPUシステムにおいては、複数のキャッシュの一貫性を制御するための仕組みがソフトウェアの実行性能に与える影響や、複数のCPUからのメモリアクセス順序を強制したり不可分操作を実現したりする仕組みをソフトウェアで明示的に利用することによる影響を考慮しなければならない場合もあります。
本書では、豊富な図説と簡潔なコードを交えながら、CPUが備える高速化のためのさまざまな仕組みとその動作を阻む要因、さらにはソフトウェアで可能な対策について、ハードウェア技術に馴染みがないプログラマーでも十分な直感を得られるように解説していきます。
本書は『n月刊ラムダノートVol.3, No.1(2021)』に掲載された記事「CPUは如何にしてソフトウェアを高速に実行するのか」を基に、同記事では概要のみ触れていた各部について掘り下げると同時に、理解を深めるためのアセンブリコードを各章に追加し、さらにマルチプロセッサに関する話題を大幅に加筆して書籍として刊行したものです。
著者紹介
Takenobu Tani
CPU関連のハードウェアエンジニア。性能と消費電力を重視するCPUの設計および応用開発に携わる。ソフトウェアの性能と電力改善の支援も担う。一番好きなプログラミング言語はHaskell、次はアセンブリ。
『n月刊ラムダノートVol.3, No.1(2021)』にて本書の前身となった記事「CPUは如何にしてソフトウェアを高速に実行するのか」を執筆(takenobu.hs 名義)。
目次
序文
第1章 CPUは如何にしてソフトウェアを高速に実行するのか
1.1 CPUはソフトウェアを「命令流」として見てる
1.2 CPUごとにどのような命令があるか
1.3 CPUで人から見えるソフトウェアをそのまま扱っていない理由
1.4 プログラムはどのようなCPUの命令列に変換されるか
第2章 命令の密度を上げるさまざまな工夫
2.1 逐次処理
2.2 パイプライン化
2.3 スーパースカラ化
2.4 スーパーパイプライン化
2.5 スーパースカラ+スーパーパイプライン化
2.6 本章のまとめ
第3章 データ依存関係
3.1 データ依存関係とは
3.2 真のデータ依存関係のスーパーパイプライン化への影響
3.3 真のデータ依存関係のスーパースカラ化への影響
3.4 アウトオブオーダー実行による緩和
3.5 再順序化(リオーダー)の必要性
3.6 真ではないデータ依存関係への影響を解消する
3.7 ソフトウェアによる緩和
3.8 命令レイテンシの計測実験
3.9 本章のまとめ
第4章 分岐命令
4.1 分岐命令とその課題
4.2 分岐命令の種類
4.3 分岐予測による緩和
4.4 分岐予測ミスの影響と要因
4.5 ソフトウェアによる緩和
4.6 予測ミス率の計測実験
4.7 本章のまとめ
第5章 キャッシュメモリ
5.1 メモリアクセスに伴うパイプラインの停滞
5.2 キャッシュメモリによる緩和
5.3 初回のアクセスは遅い(初期参照ミス)
5.4 容量を超えるアクセスは遅い(容量性ミス)
5.5 アドレスの一部が競合するアクセスも遅い(競合性ミス)
5.6 キャッシュミスの測定
5.7 本章のまとめ
第6章 仮想記憶
6.1 仮想記憶でできること
6.2 アドレス変換に伴うメモリアクセス
6.3 TLBによる緩和
6.4 TLBは外れる
6.5 ソフトウェアによる緩和
6.6 仮想記憶についての補足
6.7 TLBミスの計測実験
6.8 本章のまとめ
第7章 I/O
7.1 I/O アクセスの方法
7.2 I/O アクセスで実現できること
7.3 I/O アクセスは遅い
7.4 ハードウェアによる支援
7.5 ソフトウェアによる緩和
7.6 I/O の挙動を確認するアセンブリプログラム例
7.7 本章のまとめ
第8章 システムコール、例外、割り込み
8.1 用語の定義
8.2 システムコールとその利用シーン
8.3 例外とその利用シーン
8.4 割り込みとその利用シーン
8.5 例外・割り込み系の振る舞い
8.6 例外・割り込み系がCPUの動作を遅くする背景
8.7 ソフトウェアによる対策
8.8 システムコール、例外、割り込みについての実験
8.9 本章のまとめ
第9章 マルチプロセッサ
9.1 マルチプロセッサの多様な方式
9.2 組み合わせるCPUの種類による分類
9.3 命令流の独立性による分類
9.4 メモリアドレス空間の共有と主記憶の配置による分類
9.5 マルチプロセッサを活かすためには
9.6 データ共有によるソフトウェア間の協調
9.7 共有メモリ型マルチプロセッサ上のソフトウェアを遅くする要因
9.8 本章のまとめ
第10章 キャッシュコヒーレンス制御
10.1 CPUごとにキャッシュを搭載することの影響
10.2 キャッシュコヒーレンス制御による解決
10.3 MSI プロトコルの概要
10.4 キャッシュコヒーレンス制御は遅い
10.5 フォールスシェアリングでさらに遅い
10.6 ソフトウェアによる緩和
10.7 コヒーレンスミスについての実験
10.8 本章のまとめ
第11章 メモリ順序付け
11.1 メモリアクセスの順序は入れ替わる
11.2 メモリアクセス順序が入れ替わるメカニズム
11.3 メモリアクセス順序の入れ替えによる問題
11.4 メモリ順序付けによる解決
11.5 メモリ順序付けは遅い
11.6 ソフトウェアによる緩和
11.7 メモリ順序付けの挙動を見るプログラム
11.8 本章のまとめ
第12章 不可分操作
12.1 マルチプロセッサにおける共有データの更新
12.2 同一アドレスへの複数回のメモリアクセスの課題
12.3 不可分操作による解決
12.4 不可分操作はソフトウェアを遅くすることがある
12.5 ソフトウェアによる緩和
12.6 不可分操作についての実験
12.7 本章のまとめ
第13章 高速なソフトウェアを書く際には何に注目すべきか
13.1 性能劣化による影響の度合い
13.2 性能劣化の要因を制御できるか
13.3 結局、何を優先すればいいか
付録A CPUについてさらに広く深く知るには
A.1 書籍
A.2 学術論文など
A.3 特許文献
A.4 オープンソースハードウェア
A.5 講義資料
A.6 特定のCPUに関する情報
付録B 各CPUの基本的な命令
B.1 代表的な命令の例
B.2 命令の組み合わせ例
付録C 現代的なCPUの実装例(BOOM)
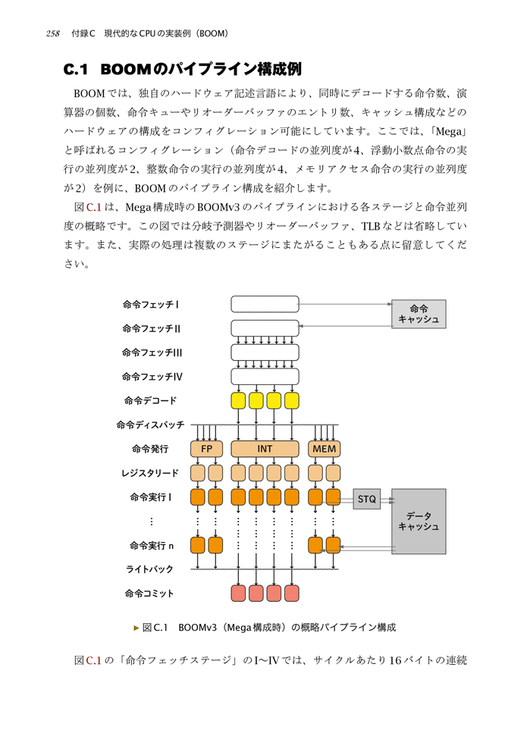
C.1 BOOMのパイプライン構成例
C.2 BOOMについての情報源
付録D マイクロオペレーション方式と、その命令レイテンシ
D.1 複雑な命令の実装方式
D.2 マイクロオペレーション方式における命令のレイテンシ
D.3 個別発行制御におけるレイテンシの揺れ
付録E GPUおよびベクトル方式におけるパイプラインの高密度化の工夫
E.1 GPUにおける高密度化のアプローチ
E.2 ベクトル方式における高密度化のアプローチ
付録F CPUの性能向上の物理的な難しさ
F.1 動作周波数と論理ゲートの段数
F.2 論理ゲートの物理的な特徴とCPU性能
あとがき
参考文献
索引
著者について